 |
|
Funciones para trabajar con "Logistic Regression": Pds::LogisticModel::FittingGradientSVM(), Pds::LogisticModel::Classify(), etc. Más...
Namespaces | |
| namespace | Pds |
| Nombre de espacion para PDS (Procesamiento Digital de Senales) | |
| namespace | Pds::LogisticModel |
| Nombre de espacio para Logistic regression. | |
Logistic regression : Clasificador | |
| Pds::Vector | Pds::LogisticModel::Classify (const Pds::Vector &W, const Pds::Matrix &X) |
| Calculo del resultado del clasificador. Más... | |
Logistic regression : Función de costo | |
| double | Pds::LogisticModel::CostCrossEntropy (const Pds::Vector &W, const Pds::Matrix &X, const Pds::Vector &Y) |
| Calculo de pesos. Más... | |
| double | Pds::LogisticModel::CostMeanSquare (const Pds::Vector &W, const Pds::Matrix &X, const Pds::Vector &Y) |
| Calculo de pesos. Más... | |
Logistic regression : Regresión de pesos | |
| Pds::Vector | Pds::LogisticModel::FittingLogitMeanSquare (Pds::IterationConf &Conf, const Pds::Matrix &X, const Pds::Vector &Y, double Delta=0.0001) |
| Calculo de pesos. Más... | |
| Pds::Vector | Pds::LogisticModel::FittingLogitMeanSquare (const Pds::Matrix &X, const Pds::Vector &Y, double Delta=0.0001) |
| Calculo de pesos. Más... | |
| Pds::Vector | Pds::LogisticModel::FittingGradientCrossEntropy (Pds::IterationConf &Conf, const Pds::Matrix &X, const Pds::Vector &Y, const Pds::Vector &W0) |
| Gradiente descendente para sigmoide. Más... | |
| Pds::Vector | Pds::LogisticModel::FittingGradientSVM (Pds::IterationConf &Conf, const Pds::Matrix &X, const Pds::Vector &Y, const Pds::Vector &W0) |
| Gradiente descendente para sigmoide. Más... | |
Logistic regression : Funciones de diagnóstico | |
| Pds::DiagnosticCurves | Pds::LogisticModel::LearningCurves (Pds::IterationConf &Conf, const Pds::Matrix &Xtr, const Pds::Vector &Ytr, const Pds::Matrix &Xcv, const Pds::Vector &Ycv, double percent) |
| Retorna learning curve. Más... | |
Funciones para trabajar con "Logistic Regression": Pds::LogisticModel::FittingGradientSVM(), Pds::LogisticModel::Classify(), etc.
| Pds::Vector Pds::LogisticModel::Classify | ( | const Pds::Vector & | W, |
| const Pds::Matrix & | X | ||
| ) |
Calculo del resultado del clasificador.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad h_{\mathbf{w}}\left(\mathbf{X}\right)=Sigmoid([1~\mathbf{X}]\mathbf{w}) \]](form_0.png)
| [in] | W | Vector de pesos. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| double Pds::LogisticModel::CostCrossEntropy | ( | const Pds::Vector & | W, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y | ||
| ) |
Calculo de pesos.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} =\left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \rightarrow \qquad h_{\mathbf{w}}\left(\mathbf{x}^{T}\right)=Sigmoid\left(\left[\overline{1}~\mathbf{x}^{T}\right]\mathbf{w}\right) \]](form_1.png)
![\[ Cost\left(\mathbf{w}\right) \quad = \quad \frac{1}{L}\sum \limits_{i}^{L} -y_{i}~log_2\left(h_{\mathbf{w}}\left(\mathbf{x}_{i}^{T}\right)\right) - \left(1-y_{i}\right)~log_2\left(1-h_{\mathbf{w}}\left(\mathbf{x}_{i}^{T}\right)\right) \]](form_2.png)
| [in] | W | Vector de pesos. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector de datos de salida. |
| double Pds::LogisticModel::CostMeanSquare | ( | const Pds::Vector & | W, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y | ||
| ) |
Calculo de pesos.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} =\left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \rightarrow \qquad h_{\mathbf{w}}\left(\mathbf{X}\right)=Sigmoid\left(\left[\overline{1}~\mathbf{X}\right]\mathbf{w}\right) \]](form_3.png)
![\[ Cost\left(\mathbf{w}\right) = \frac{1}{L}||h_{\mathbf{w}}\left(\mathbf{X}\right)-\mathbf{y}||^2 = \frac{1}{L}\sum \limits_{i}^{L} \left(h_{\mathbf{w}}\left(\mathbf{x}_i^{T}\right)-y_i\right)^2 \]](form_4.png)
| [in] | W | Vector de pesos. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector de datos de salida. |
| Pds::Vector Pds::LogisticModel::FittingLogitMeanSquare | ( | Pds::IterationConf & | Conf, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y, | ||
| double | Delta = 0.0001 |
||
| ) |
Calculo de pesos.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} =\left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \rightarrow \qquad \mathbf{R} = \left(\begin{matrix} 1 & \mathbf{X}\\ \end{matrix}\right), \qquad \mathbf{y_o} = \delta+(1-2 \delta)\mathbf{y}. \]](form_5.png)
![\[ \begin{array}{l} if(rcond>=Pds::Ml::WarningRCond) \\ \qquad \mathbf{w} = \left(\mathbf{R}^{T}\mathbf{R}\right)^{-1} \mathbf{R}^{T} logit(\mathbf{y_o}) \qquad with \qquad Cost(\mathbf{w}) \equiv \frac{1}{L}||\mathbf{R}\mathbf{w}-logit(\mathbf{y_o})||^2 \\ else\\ \qquad \mathbf{w} \leftarrow \left(\mathbf{R}^{T}\mathbf{R}+\frac{\gamma L}{N}\mathbf{I}\right)^{-1} \left(\mathbf{R}^{T} logit(\mathbf{y_o})-\mathbf{R}^{T}\mathbf{R} \mathbf{w} \right) \qquad with \qquad Cost(\mathbf{w}) \equiv \frac{1}{L}||\mathbf{R}\mathbf{w}-logit(\mathbf{y_o})||^2+\frac{\gamma}{N}||\mathbf{w}-\mathbf{w}_{last}||^2 \end{array} \]](form_6.png)
| [in] | Conf | Configuraciones para algun algoritmo que itera. |
| [in] | X | Vector de datos 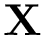 . . |
| [in] | Y | Vector de datos 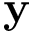 . . |
| [in] | Delta | Valor 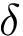 . . |
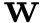 si el calculo es posible o una vacio si no existe inversa de
si el calculo es posible o una vacio si no existe inversa de 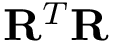 .
. | Pds::Vector Pds::LogisticModel::FittingLogitMeanSquare | ( | const Pds::Matrix & | X, |
| const Pds::Vector & | Y, | ||
| double | Delta = 0.0001 |
||
| ) |
Calculo de pesos.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} = \left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \rightarrow \qquad \mathbf{R} = \left(\begin{matrix} 1 & \mathbf{X}\\ \end{matrix}\right), \qquad \mathbf{y_o} = \delta+(1-2 \delta)\mathbf{y}, \qquad Cost(\mathbf{w}) \equiv \frac{1}{L}||\mathbf{R}\mathbf{w}-logit(\mathbf{y_o})||^2. \]](form_12.png)
![\[ \begin{array}{l} if(rcond>=Pds::Ml::WarningRCond) \\ \qquad \mathbf{w} = \left(\mathbf{R}^{T}\mathbf{R}\right)^{-1} \mathbf{R}^{T} logit(\mathbf{y_o}) \\ else\\ \qquad \mathbf{w} = [] \end{array} \]](form_13.png)
| [in] | X | Vector de datos . |
| [in] | Y | Vector de datos . |
| [in] | Delta | Valor . |
si el calculo es posible o una vacio si no existe inversa de . | Pds::Vector Pds::LogisticModel::FittingGradientCrossEntropy | ( | Pds::IterationConf & | Conf, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y, | ||
| const Pds::Vector & | W0 | ||
| ) |
Gradiente descendente para sigmoide.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} = \left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \rightarrow \qquad \mathbf{R} = [\mathbf{1}\quad \mathbf{X}], \qquad h_{\mathbf{w}}(\mathbf{X}) \leftarrow Sigmoid(\mathbf{R} \mathbf{w}), \qquad \mathbf{I}_b= \left(\begin{matrix} 0 & 0 & 0 & ... & 0\\ 0 & 1 & 0 & ... & 0\\ 0 & 0 & 1 & ... & 0\\ \vdots & \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & 0 & ... & 1 \end{matrix}\right) \]](form_14.png)
![\[ Cost\left(\mathbf{w}\right) = \frac{1}{L}\sum \limits_{i}^{L} \left\{ -y_{i} ~ log_2\left(h_{\mathbf{w}}\left(\mathbf{x}_{i}^{T}\right)\right) ~ - \left(1-y_{i}\right) ~ log_2\left(1-h_{\mathbf{w}}\left(\mathbf{x}_{i}^{T}\right)\right) \right\} \qquad +\qquad \frac{\lambda}{2N}||\mathbf{I}_b\mathbf{w}||^2 \]](form_15.png)
![\[ Repetir: \qquad \mathbf{w} \leftarrow \mathbf{w} - \alpha \left\{ \frac{1}{L} \mathbf{R}^{T} \left( h_{\mathbf{w}}(\mathbf{X})-\mathbf{y} \right) \quad + \quad \frac{\lambda}{N} \mathbf{I}_b\mathbf{w} \right\}. \]](form_16.png)
| [in] | Conf | Valores de configuracion de la iteracion. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector resultados . |
| [in] | W0 | Primeiro valor de . |
| Pds::Vector Pds::LogisticModel::FittingGradientSVM | ( | Pds::IterationConf & | Conf, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y, | ||
| const Pds::Vector & | W0 | ||
| ) |
Gradiente descendente para sigmoide.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} = \left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \rightarrow \qquad \mathbf{\hat{y}}=2\mathbf{y}-1, \qquad \mathbf{R} = [\mathbf{1}\quad \mathbf{X}], \qquad \mathbf{r}^{T} = [\mathbf{1}\quad \mathbf{x}^{T}], \qquad \mathbf{I}_b= \left(\begin{matrix} 0 & 0 & 0 & ... & 0\\ 0 & 1 & 0 & ... & 0\\ 0 & 0 & 1 & ... & 0\\ \vdots & \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & 0 & ... & 1 \end{matrix}\right) \]](form_17.png)
![\[ \begin{matrix} Cost\left(\mathbf{w}\right) & = & \frac{1}{L}\sum \limits_{i}^{L} \left\{ y_{i} ~ Cost_{1}\left(\mathbf{r}^{T}\mathbf{w}\right) ~ + \left(1-y_{i}\right) ~ Cost_{0}\left(\mathbf{r}^{T}\mathbf{w}\right) \right\} & + & \frac{\lambda}{2N}||\mathbf{I}_b\mathbf{w}||^2\\ ~ & = & \frac{1}{L}\sum \limits_{i}^{L} Max\{0,1-\hat{y}_{i}\mathbf{r}^{T}\mathbf{w}\} & + & \frac{\lambda}{2N}||\mathbf{I}_b\mathbf{w}||^2\\ \end{matrix} \]](form_18.png)
![\[ \phi_{y}(z)= \left\{ \begin{matrix} -y & ; & z<-1\\ 1-2y & ; & -1 \leq z \leq +1\\ 1-y & ; & +1 \leq z \end{matrix} \right. \]](form_19.png)
![\[ Repetir: \qquad \mathbf{w} \leftarrow \mathbf{w} - \alpha \left\{ \frac{1}{L} \mathbf{R}^{T} \phi_{\mathbf{y}}(\mathbf{R}\mathbf{w}) \quad + \quad \frac{\lambda}{N} \mathbf{I}_b\mathbf{w} \right\}. \]](form_20.png)
| [in] | Conf | Valores de configuracion de la iteracion. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector resultados . |
| [in] | W0 | Primeiro valor de . |
| Pds::DiagnosticCurves Pds::LogisticModel::LearningCurves | ( | Pds::IterationConf & | Conf, |
| const Pds::Matrix & | Xtr, | ||
| const Pds::Vector & | Ytr, | ||
| const Pds::Matrix & | Xcv, | ||
| const Pds::Vector & | Ycv, | ||
| double | percent | ||
| ) |
Retorna learning curve.
![\[ \mathbf{R} \leftarrow [\mathbf{1}\quad \mathbf{X}]\]](form_21.png)
![\[ h_{\mathbf{w}}(\mathbf{X}) \leftarrow Sigmoid(\mathbf{R} \mathbf{w})\]](form_22.png)
| [in,out] | Conf | Valores de configuracion de la iteracion. |
| [in] | Xtr | Datos X de entrenamiento. |
| [in] | Ytr | Datos Y de entrenamiento. |
| [in] | Xcv | Datos X de cross-validation. |
| [in] | Ycv | Datos Y de cross-validation. |
| [in] | percent | Porcentaje de datos testados. |







 1.9.2
1.9.2