Funciones para trabajar con "Data sets": Pds::DataSet::AllIndices(), Pds::DataSet::Split(), etc.
Más...
|
| namespace | Pds |
| | Nombre de espacio para Pds (Procesamiento Digital de Senales)
|
| |
| namespace | Pds::DataSet |
| | Nombre de espacio para DataSet (Funciones para manipulación de data sets)
|
| |
|
Salva datos de matrices
|
| Pds::DataSetBlock | Pds::DataSet::Split (const Pds::Matrix &X, const Pds::Vector &Y, double Training, double CrossVal, double Test) |
| | Divide un data set en 3 data set: {Training, CrossValidation, Test}, selecionados aleatoriamente sin repetición. Más...
|
| |
| Pds::DataSetBlock | Pds::DataSet::SplitAndScaling (const Pds::Matrix &X, const Pds::Vector &Y, double Training, double CrossVal, double Test, Pds::Vector &Std, Pds::Vector &Mean) |
| | Divide un data set en 3 data set: {Training, CrossValidation, Test}, selecionados aleatoriamente sin repetición. Más...
|
| |
| double | Pds::DataSet::Volume (const Pds::Matrix &X) |
| | Calcula el volumen del dataset. Más...
|
| |
| double | Pds::DataSet::VolumeInValidDims (const Pds::Matrix &X) |
| | Calcula el volumen del dataset en dimenciones com min diferente de max. Más...
|
| |
| double | Pds::DataSet::InterDistance (const Pds::Matrix &X) |
| | Calcula la interdistancia 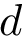 entre las entre las 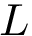 muestras de muestras de 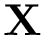 , donde cada muestra , donde cada muestra 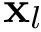 de tiene dimensión de tiene dimensión 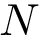 . Más... . Más...
|
| |
|
Salva datos de matrices
|
| bool | Pds::DataSet::GetBestIGThreshold (const Pds::Vector &V, const Pds::Vector &Y, double YUmbral, unsigned int MinID, double &ValUmbral, double &BestIG, unsigned int &Sign) |
| | Retorna el mejor quiebre del vector V para obtener la mayor Information Gain ( 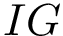 ). Más... ). Más...
|
| |
Funciones para trabajar con "Data sets": Pds::DataSet::AllIndices(), Pds::DataSet::Split(), etc.
#include <Pds/FuncDataSet>
◆ AllIndices()
| Pds::DataSetIndices Pds::DataSet::AllIndices |
( |
unsigned int |
N, |
|
|
double |
Training, |
|
|
double |
CrossVal, |
|
|
double |
Test |
|
) |
| |
Calcula indices para {Training, CrossValidation, Test}, selecionados aleatoriamente sin repetición.
- Parámetros
-
| [in] | N | Numero de muestras. |
| [in] | Training | Porcion de las N muestras. |
| [in] | CrossVal | Porcion de las N muestras. |
| [in] | Test | Porcion de las N muestras. |
- Devuelve
- Retorna indices para {Training, CrossValidation, Test}.
◆ Split()
| Pds::DataSetBlock Pds::DataSet::Split |
( |
const Pds::Matrix & |
X, |
|
|
const Pds::Vector & |
Y, |
|
|
double |
Training, |
|
|
double |
CrossVal, |
|
|
double |
Test |
|
) |
| |
◆ SplitAndScaling()
| Pds::DataSetBlock Pds::DataSet::SplitAndScaling |
( |
const Pds::Matrix & |
X, |
|
|
const Pds::Vector & |
Y, |
|
|
double |
Training, |
|
|
double |
CrossVal, |
|
|
double |
Test, |
|
|
Pds::Vector & |
Std, |
|
|
Pds::Vector & |
Mean |
|
) |
| |
Divide un data set en 3 data set: {Training, CrossValidation, Test}, selecionados aleatoriamente sin repetición.
- Parámetros
-
| [in] | X | Data X |
| [in] | Y | Data Y. |
| [in] | Training | Porcion del total de muestras. |
| [in] | CrossVal | Porcion del total de muestras. |
| [in] | Test | Porcion del total de muestras. |
| [out] | Std | Desvio padrao de cada coluna. |
| [out] | Mean | Média de cada coluna. |
- Devuelve
- Retorna un bloque de datos con data set para {Training, CrossValidation, Test}.
◆ Volume()
| double Pds::DataSet::Volume |
( |
const Pds::Matrix & |
X | ) |
|
Calcula el volumen del dataset.
![\[\prod_i \left(max\{x_i\}-min\{x_i\}\right)\]](form_3.png)
- Parámetros
-
- Devuelve
- Retorna el volumen del dataset.
◆ VolumeInValidDims()
| double Pds::DataSet::VolumeInValidDims |
( |
const Pds::Matrix & |
X | ) |
|
Calcula el volumen del dataset en dimenciones com min diferente de max.
![\[\prod_i if(max\{x_i\}\neq min\{x_i\})~ \left(max\{x_i\}-min\{x_i\}\right)\]](form_4.png)
- Parámetros
-
- Devuelve
- Retorna el volumen del dataset.
◆ InterDistance()
| double Pds::DataSet::InterDistance |
( |
const Pds::Matrix & |
X | ) |
|
◆ GetBestIGThreshold()
| bool Pds::DataSet::GetBestIGThreshold |
( |
const Pds::Vector & |
V, |
|
|
const Pds::Vector & |
Y, |
|
|
double |
YUmbral, |
|
|
unsigned int |
MinID, |
|
|
double & |
ValUmbral, |
|
|
double & |
BestIG, |
|
|
unsigned int & |
Sign |
|
) |
| |

![\[d=\sqrt[N]{\frac{Pds::DataSet::Volume(\mathbf{X})}{L}}\]](form_10.png)
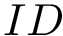 .
. 






 1.9.2
1.9.2