 |
|
Funciones para trabajar con "Logistic Regression": Pds::LogisticModel::FittingGradientSVM(), Pds::LogisticModel::Classify(), etc. Más...
Namespaces | |
| namespace | Pds |
| Nombre de espacio para Pds (Procesamiento Digital de Senales) | |
| namespace | Pds::LogisticModel |
| Nombre de espacio para LogisticModel (Logistic regression) | |
Logistic regression : Clasificador | |
| Pds::Vector | Pds::LogisticModel::Classify (const Pds::Vector &W, const Pds::Matrix &X) |
| Calculo del resultado del clasificador. Más... | |
Logistic regression : Función de costo | |
| double | Pds::LogisticModel::CostInformationGain (const Pds::Vector &W, const Pds::Matrix &X, const Pds::Vector &Y) |
| Calculo de costo. Más... | |
| Pds::Vector | Pds::LogisticModel::GradientCostInformationGain (const Pds::Vector &W, const Pds::Matrix &X, const Pds::Vector &Y, double h) |
| Calculo de costo. Más... | |
| double | Pds::LogisticModel::CostCrossEntropy (const Pds::Vector &W, const Pds::Matrix &X, const Pds::Vector &Y) |
| Calculo de pesos. Más... | |
| double | Pds::LogisticModel::CostMeanSquare (const Pds::Vector &W, const Pds::Matrix &X, const Pds::Vector &Y) |
| Calculo de pesos. Más... | |
Logistic regression : Peso inicial | |
| Pds::Vector | Pds::LogisticModel::GetW0MeanMethod (const Pds::Matrix &X) |
Obtiene de forma rapida un vector 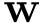 inicial para usar en regresion logistica. Más... inicial para usar en regresion logistica. Más... | |
| Pds::Vector | Pds::LogisticModel::GetW0CornerMeanMethod (const Pds::Matrix &X) |
| Obtiene de forma rapida un vector inicial para usar en regresion logistica. Más... | |
| Pds::Vector | Pds::LogisticModel::GetW0MeanSquareMethod (const Pds::Matrix &X) |
| Obtiene de forma rapida un vector inicial para usar en regresion logistica. Más... | |
Logistic regression : Regresión de pesos : Familia Mean Square | |
| Pds::Vector | Pds::LogisticModel::FittingLogitMeanSquare (Pds::IterationConf &Conf, const Pds::Matrix &X, const Pds::Vector &Y, double Delta=0.0001) |
| Calculo de pesos. Más... | |
| Pds::Vector | Pds::LogisticModel::FittingLogitMeanSquare (const Pds::Matrix &X, const Pds::Vector &Y, double Delta=0.0001) |
| Calculo de pesos. Más... | |
| Pds::Vector | Pds::LogisticModel::FittingLogitWeightedMeanSquare (Pds::IterationConf &Conf, const Pds::Matrix &X, const Pds::Vector &Y, const Pds::Vector &D, double Delta=0.0001) |
| Calculo de pesos. Más... | |
| Pds::Vector | Pds::LogisticModel::FittingLogitWeightedMeanSquare (const Pds::Matrix &X, const Pds::Vector &Y, const Pds::Vector &D, double Delta=0.0001) |
| Calculo de pesos. Más... | |
Logistic regression : Regresión de pesos : Familia Cross Entropy | |
| Pds::Vector | Pds::LogisticModel::FittingGradientCrossEntropy (Pds::IterationConf &Conf, const Pds::Matrix &X, const Pds::Vector &Y, const Pds::Vector &W0) |
| Gradiente descendente para sigmoide. Más... | |
| Pds::Vector | Pds::LogisticModel::FittingGradientSVM (Pds::IterationConf &Conf, const Pds::Matrix &X, const Pds::Vector &Y, const Pds::Vector &W0) |
| Gradiente descendente para sigmoide. Más... | |
Logistic regression : Regresión de pesos : Familia Information Gain | |
| Pds::Vector | Pds::LogisticModel::FittingOrtogonalIG (const Pds::Matrix &X, const Pds::Vector &Y, unsigned int MinID) |
| Calculo de pesos. Más... | |
| Pds::Vector | Pds::LogisticModel::FittingGradientIG (Pds::IterationConf &Conf, const Pds::Matrix &X, const Pds::Vector &Y, const Pds::Vector &W0) |
| Calculo de pesos. Más... | |
Logistic regression : Funciones de diagnóstico | |
| Pds::DiagnosticCurves | Pds::LogisticModel::LearningCurves (Pds::IterationConf &Conf, const Pds::Matrix &Xtr, const Pds::Vector &Ytr, const Pds::Matrix &Xcv, const Pds::Vector &Ycv, double percent) |
| Retorna learning curve. Más... | |
Funciones para trabajar con "Logistic Regression": Pds::LogisticModel::FittingGradientSVM(), Pds::LogisticModel::Classify(), etc.
| Pds::Vector Pds::LogisticModel::Classify | ( | const Pds::Vector & | W, |
| const Pds::Matrix & | X | ||
| ) |
Calculo del resultado del clasificador.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad h_{\mathbf{w}}\left(\mathbf{X}\right)=Sigmoid([1~\mathbf{X}]\mathbf{w}) \]](form_0.png)
| [in] | W | Vector de pesos. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| double Pds::LogisticModel::CostInformationGain | ( | const Pds::Vector & | W, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y | ||
| ) |
Calculo de costo.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} =\left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right) \qquad \rightarrow \qquad \mathbf{u} =\left(\begin{matrix} 1\\ 1\\ \vdots\\ 1\\ \end{matrix}\right) \]](form_1.png)
![\[ \mathbf{z}\left(\mathbf{w}\right)=Sigmoid\left(\left[\overline{1}~\mathbf{X}\right]\mathbf{w}\right), \quad \mathbf{\bar{z}}\left(\mathbf{w}\right)=round(\mathbf{z}) \]](form_2.png)
Calculado desde el punto de vista matemático
![\[ N_t=\mathbf{u}^{T}\mathbf{y}, \quad N_a\left(\mathbf{w}\right)= \mathbf{u}^{T}\mathbf{\bar{z}}\left(\mathbf{w}\right) \quad N_1\left(\mathbf{w}\right)= \mathbf{y}^{T}\mathbf{\bar{z}}\left(\mathbf{w}\right) \]](form_3.png)
![\[ Cost\left(\mathbf{w}\right) \quad = \quad h_b \left(\frac{N_t}{L}\right) -\frac{N_a\left(\mathbf{w}\right)}{L}~h_b \left(\frac{N_1\left(\mathbf{w}\right)}{N_a\left(\mathbf{w}\right)}\right) -\frac{L-N_a\left(\mathbf{w}\right)}{L}~h_b \left(\frac{N_t-N_1\left(\mathbf{w}\right)}{L-N_a\left(\mathbf{w}\right)}\right) \]](form_4.png)
Calculado desde el punto de vista programático
![\[ \mathbf{\hat{y}} =\left(\begin{matrix} \mathbf{y}_{0}\\ \mathbf{y}_{1} \end{matrix}\right), \quad \mathbf{y}_{0}=\mathbf{y}_{\mathbf{\bar{z}}\equiv \bar{0}}, \quad \mathbf{y}_{1}=\mathbf{y}_{\mathbf{\bar{z}}\equiv \bar{1}} \]](form_5.png)
![\[ Cost\left(\mathbf{w}\right) \quad = \quad h_b \left(p_{\mathbf{\hat{y}}}\right) -\frac{N_{\mathbf{y}_{1}}}{L}~h_b \left(p_{\mathbf{y}_1}\right) -\frac{N_{\mathbf{y}_{0}}}{L}~h_b \left(p_{\mathbf{y}_0}\right) \]](form_6.png)
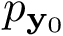 es la probabilidad de 1s en el vector
es la probabilidad de 1s en el vector 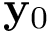
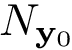 es el número de elementos en el vector
es el número de elementos en el vector
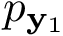 es la probabilidad de 1s en el vector
es la probabilidad de 1s en el vector 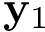
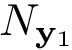 es el número de elementos en el vector
es el número de elementos en el vector
| [in] | W | Vector de pesos. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector de datos de salida. |
| Pds::Vector Pds::LogisticModel::GradientCostInformationGain | ( | const Pds::Vector & | W, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y, | ||
| double | h | ||
| ) |
Calculo de costo.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} =\left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \mathbf{w} =\left(\begin{matrix} w_0\\ w_1\\ \vdots\\ w_N\\ \end{matrix}\right) \]](form_13.png)
![\[ C(\mathbf{w})\equiv Pds::LogisticModel::CostInformationGain(\mathbf{w},\mathbf{X},\mathbf{y}) \]](form_14.png)
![\[ \mathbf{h}_n =(0,0,...,0,...,0,0), \quad \mathbf{h}_n(n)=h; \]](form_15.png)
![\[ \nabla C(\mathbf{w}) \equiv \frac{\partial C(\mathbf{w})}{\partial \mathbf{w}} \equiv \left(\begin{matrix} \frac{\partial C(\mathbf{w})}{\partial w_0}\\ \frac{\partial C(\mathbf{w})}{\partial w_1}\\ \vdots\\ \frac{\partial C(\mathbf{w})}{\partial w_N}\\ \end{matrix}\right) \approx \left(\begin{matrix} \frac{ C(\mathbf{w}+\mathbf{h}_0) - C(\mathbf{w}-\mathbf{h}_0)}{2h}\\ \frac{ C(\mathbf{w}+\mathbf{h}_1) - C(\mathbf{w}-\mathbf{h}_1)}{2h}\\ \vdots\\ \frac{ C(\mathbf{w}+\mathbf{h}_N) - C(\mathbf{w}-\mathbf{h}_N)}{2h}\\ \end{matrix}\right) \]](form_16.png)
| [in] | W | Vector de pesos. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector de datos de salida. |
| [in] | h | Paso para aplicar la. |
| double Pds::LogisticModel::CostCrossEntropy | ( | const Pds::Vector & | W, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y | ||
| ) |
Calculo de pesos.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} =\left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \rightarrow \qquad h_{\mathbf{w}}\left(\mathbf{x}^{T}\right)=Sigmoid\left(\left[\overline{1}~\mathbf{X}\right]\mathbf{w}\right) \]](form_17.png)
![\[ Cost\left(\mathbf{w}\right) \quad = \quad \frac{1}{L}\sum \limits_{i}^{L} -y_{i}~log_2\left(h_{\mathbf{w}}\left(\mathbf{x}_{i}^{T}\right)\right) - \left(1-y_{i}\right)~log_2\left(1-h_{\mathbf{w}}\left(\mathbf{x}_{i}^{T}\right)\right) \]](form_18.png)
| [in] | W | Vector de pesos. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector de datos de salida. |
| double Pds::LogisticModel::CostMeanSquare | ( | const Pds::Vector & | W, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y | ||
| ) |
Calculo de pesos.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} =\left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \rightarrow \qquad h_{\mathbf{w}}\left(\mathbf{X}\right)=Sigmoid\left(\left[\overline{1}~\mathbf{X}\right]\mathbf{w}\right) \]](form_19.png)
![\[ Cost\left(\mathbf{w}\right) = \frac{1}{L}||h_{\mathbf{w}}\left(\mathbf{X}\right)-\mathbf{y}||^2 = \frac{1}{L}\sum \limits_{i}^{L} \left(h_{\mathbf{w}}\left(\mathbf{x}_i^{T}\right)-y_i\right)^2 \]](form_20.png)
| [in] | W | Vector de pesos. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector de datos de salida. |
| Pds::Vector Pds::LogisticModel::GetW0MeanMethod | ( | const Pds::Matrix & | X | ) |
Obtiene de forma rapida un vector inicial para usar en regresion logistica.
![\[z=mean\_of\_columns(X),\qquad N=X.Ncol()\equiv z.Nel()\]](form_22.png)
![\[\mathbf{w}=[w_0,~w_1,~...,w_N]^T\]](form_23.png)
![\[w_{0}=-\sum_{n=1}^{N} z_{i},\qquad w_1=w_2=...w_N=1\]](form_24.png)
| [in] | X | Vector de datos 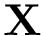 . . |
inicial para usar en regresion logistica. | Pds::Vector Pds::LogisticModel::GetW0CornerMeanMethod | ( | const Pds::Matrix & | X | ) |
Obtiene de forma rapida un vector inicial para usar en regresion logistica.
| [in] | X | Vector de datos . |
inicial para usar en regresion logistica. | Pds::Vector Pds::LogisticModel::GetW0MeanSquareMethod | ( | const Pds::Matrix & | X | ) |
Obtiene de forma rapida un vector inicial para usar en regresion logistica.
![\[si~\mathbf{X}=[\mathbf{x}_1,~\mathbf{x}_1,~...,~\mathbf{x}_N]\]](form_26.png)
![\[\mathbf{R}=[\mathbf{1},~\mathbf{x}_1,~...,~\mathbf{x}_N]\]](form_27.png)
![\[\mathbf{v}=(\mathbf{R}^T\mathbf{R})^{-1}\mathbf{R}^T\mathbf{x}_1\]](form_28.png)
![\[\mathbf{v}=[v_1,~v_2,~v_3,~...,~v_N]\]](form_29.png)
![\[\mathbf{W}=[v_1,~-1,~v_2,~v_3,~...,~v_N]\]](form_30.png)
| [in] | X | Vector de datos . |
inicial para usar en regresion logistica. | Pds::Vector Pds::LogisticModel::FittingLogitMeanSquare | ( | Pds::IterationConf & | Conf, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y, | ||
| double | Delta = 0.0001 |
||
| ) |
Calculo de pesos.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} =\left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \rightarrow \qquad \mathbf{R} = \left(\begin{matrix} 1 & \mathbf{X}\\ \end{matrix}\right), \qquad \mathbf{y_o} = \delta+(1-2 \delta)\mathbf{y}. \]](form_31.png)
![\[ \begin{array}{l} if(rcond>=Pds::Ml::WarningRCond) \\ \qquad \mathbf{w} = \left(\mathbf{R}^{T}\mathbf{R}\right)^{-1} \mathbf{R}^{T} logit(\mathbf{y_o})\\ \qquad with \qquad Cost(\mathbf{w}) \equiv \frac{1}{L}||\mathbf{R}\mathbf{w}-logit(\mathbf{y_o})||^2 \\ else\\ \qquad \mathbf{w} \leftarrow \mathbf{w} +\left(\mathbf{R}^{T}\mathbf{R}+\frac{\gamma L}{N}\mathbf{I}\right)^{-1} \left(\mathbf{R}^{T} logit(\mathbf{y_o})-\mathbf{R}^{T}\mathbf{R} \mathbf{w} \right)\\ \qquad with \qquad Cost(\mathbf{w}) \equiv \frac{1}{L}||\mathbf{R}\mathbf{w}-logit(\mathbf{y_o})||^2+\frac{\gamma}{N}||\mathbf{w}-\mathbf{w}_{last}||^2 \end{array} \]](form_32.png)
| [in] | Conf | Configuraciones para algun algoritmo que itera. |
| [in] | X | Vector de datos . |
| [in] | Y | Vector de datos 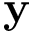 . . |
| [in] | Delta | Valor 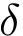 . . |
si el calculo es posible o una vacio si no existe inversa de 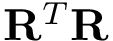 .
. | Pds::Vector Pds::LogisticModel::FittingLogitMeanSquare | ( | const Pds::Matrix & | X, |
| const Pds::Vector & | Y, | ||
| double | Delta = 0.0001 |
||
| ) |
Calculo de pesos.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} = \left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \]](form_36.png)
![\[ \mathbf{R} = \left(\begin{matrix} 1 & \mathbf{X}\\ \end{matrix}\right), \qquad \mathbf{y_o} = \delta+(1-2 \delta)\mathbf{y}, \qquad Cost(\mathbf{w}) \equiv \frac{1}{L}||\mathbf{R}\mathbf{w}-logit(\mathbf{y_o})||^2. \]](form_37.png)
![\[ \begin{array}{l} if(rcond>=Pds::Ml::WarningRCond) \\ \qquad \mathbf{w} = \left(\mathbf{R}^{T}\mathbf{R}\right)^{-1} \mathbf{R}^{T} logit(\mathbf{y_o}) \\ else\\ \qquad \mathbf{w} = [] \end{array} \]](form_38.png)
| [in] | X | Vector de datos . |
| [in] | Y | Vector de datos . |
| [in] | Delta | Valor . |
si el calculo es posible o una vacio si no existe inversa de . | Pds::Vector Pds::LogisticModel::FittingLogitWeightedMeanSquare | ( | Pds::IterationConf & | Conf, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y, | ||
| const Pds::Vector & | D, | ||
| double | Delta = 0.0001 |
||
| ) |
Calculo de pesos.
![\[ \begin{array}{l} if(rcond>=Pds::Ml::WarningRCond) \\ \qquad \mathbf{w} = \left(\mathbf{R}^{T} \mathbf{A} \mathbf{R}\right)^{-1} \mathbf{R}^{T} \mathbf{A} logit(\mathbf{y_o})\\ \qquad with \qquad Cost(\mathbf{w}) \equiv \frac{1}{L}||\mathbf{R}\mathbf{w}-logit(\mathbf{y_o})||^2_{\mathbf{A}} \\ else\\ \qquad \mathbf{w} \leftarrow \mathbf{w} +\left(\mathbf{R}^{T} \mathbf{A} \mathbf{R}+\frac{\gamma L}{N}\mathbf{I}\right)^{-1} \left(\mathbf{R}^{T} \mathbf{A} logit(\mathbf{y_o})-\mathbf{R}^{T}\mathbf{R} \mathbf{w} \right)\\ \qquad with \qquad Cost(\mathbf{w}) \equiv \frac{1}{L}||\mathbf{R}\mathbf{w}-logit(\mathbf{y_o})||^2_{\mathbf{A}}+\frac{\gamma}{N}||\mathbf{w}-\mathbf{w}_{last}||^2 \end{array} \]](form_39.png)
| [in] | Conf | Configuraciones para algun algoritmo que itera. |
| [in] | X | Vector de datos . |
| [in] | Y | Vector de datos . |
| [in] | D | Vector 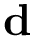 para formar para formar 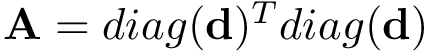 . . |
| [in] | Delta | Valor . |
si el calculo es posible o una vacio si no existe inversa de . | Pds::Vector Pds::LogisticModel::FittingLogitWeightedMeanSquare | ( | const Pds::Matrix & | X, |
| const Pds::Vector & | Y, | ||
| const Pds::Vector & | D, | ||
| double | Delta = 0.0001 |
||
| ) |
Calculo de pesos.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right), \qquad \mathbf{y} = \left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \qquad \mathbf{A}=diag(\mathbf{d})^T diag(\mathbf{d}) \]](form_42.png)
![\[ \mathbf{R} = \left(\begin{matrix} 1 & \mathbf{X}\\ \end{matrix}\right), \qquad \mathbf{y_o} = \delta+(1-2 \delta)\mathbf{y}, \qquad Cost(\mathbf{w}) \equiv \frac{1}{L}||\mathbf{R}\mathbf{w}-logit(\mathbf{y_o})||^2_{\mathbf{A}}. \]](form_43.png)
![\[ \begin{array}{l} if(rcond>=Pds::Ml::WarningRCond) \\ \qquad \mathbf{w} = \left(\mathbf{R}^{T}\mathbf{A}\mathbf{R}\right)^{-1} \mathbf{R}^{T} \mathbf{A} logit(\mathbf{y_o}) \\ else\\ \qquad \mathbf{w} = [] \end{array} \]](form_44.png)
| [in] | X | Vector de datos . |
| [in] | Y | Vector de datos . |
| [in] | D | Vector para formar . |
| [in] | Delta | Valor . |
si el calculo es posible o una vacio si no existe inversa de . | Pds::Vector Pds::LogisticModel::FittingGradientCrossEntropy | ( | Pds::IterationConf & | Conf, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y, | ||
| const Pds::Vector & | W0 | ||
| ) |
Gradiente descendente para sigmoide.
![\[ \mathbf{R} = [\mathbf{1}\quad \mathbf{X}], \qquad h_{\mathbf{w}}(\mathbf{X}) \leftarrow Sigmoid(\mathbf{R} \mathbf{w}), \qquad \mathbf{I}_b= \left(\begin{matrix} 0 & 0 & 0 & ... & 0\\ 0 & 1 & 0 & ... & 0\\ 0 & 0 & 1 & ... & 0\\ \vdots & \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & 0 & ... & 1 \end{matrix}\right) \]](form_45.png)
![\[ Cost\left(\mathbf{w}\right) = \frac{1}{L}\sum \limits_{i}^{L} \left\{ -y_{i} ~ log_2\left(h_{\mathbf{w}}\left(\mathbf{x}_{i}^{T}\right)\right) ~ - \left(1-y_{i}\right) ~ log_2\left(1-h_{\mathbf{w}}\left(\mathbf{x}_{i}^{T}\right)\right) \right\} \qquad +\qquad \frac{\lambda}{2N}||\mathbf{I}_b\mathbf{w}||^2 \]](form_46.png)
![\[ Repetir: \qquad \mathbf{w} \leftarrow \mathbf{w} - \alpha \left\{ \frac{1}{L} \mathbf{R}^{T} \left( h_{\mathbf{w}}(\mathbf{X})-\mathbf{y} \right) \quad + \quad \frac{\lambda}{N} \mathbf{I}_b\mathbf{w} \right\}. \]](form_47.png)
| [in] | Conf | Valores de configuracion de la iteracion. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector resultados . |
| [in] | W0 | Primeiro valor de . |
| Pds::Vector Pds::LogisticModel::FittingGradientSVM | ( | Pds::IterationConf & | Conf, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y, | ||
| const Pds::Vector & | W0 | ||
| ) |
Gradiente descendente para sigmoide.
![\[ \mathbf{\hat{y}}=2\mathbf{y}-1, \qquad \mathbf{R} = [\mathbf{1}\quad \mathbf{X}], \qquad \mathbf{r}^{T} = [\mathbf{1}\quad \mathbf{x}^{T}], \qquad \mathbf{I}_b= \left(\begin{matrix} 0 & 0 & 0 & ... & 0\\ 0 & 1 & 0 & ... & 0\\ 0 & 0 & 1 & ... & 0\\ \vdots & \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & 0 & ... & 1 \end{matrix}\right) \]](form_48.png)
![\[ \begin{matrix} Cost\left(\mathbf{w}\right) & = & \frac{1}{L}\sum \limits_{i}^{L} \left\{ y_{i} ~ Cost_{1}\left(\mathbf{r}^{T}\mathbf{w}\right) ~ + \left(1-y_{i}\right) ~ Cost_{0}\left(\mathbf{r}^{T}\mathbf{w}\right) \right\} & + & \frac{\lambda}{2N}||\mathbf{I}_b\mathbf{w}||^2\\ ~ & = & \frac{1}{L}\sum \limits_{i}^{L} Max\{0,1-\hat{y}_{i}\mathbf{r}^{T}\mathbf{w}\} & + & \frac{\lambda}{2N}||\mathbf{I}_b\mathbf{w}||^2\\ \end{matrix} \]](form_49.png)
![\[ -log\left(\frac{1}{1+e^{-z}}\right) \approx Cost_{1}\left(z\right)=Cost_{0}\left(-z\right) = (1-z)(0\leq (1-z)) \]](form_50.png)
![\[ \frac{\partial Max\{0,1-(2 y-1) z \} }{\partial z} \equiv \phi_{y}(z)= \left\{ \begin{matrix} -y & ; & z<-1\\ 1-2y & ; & -1 \leq z \leq +1\\ 1-y & ; & +1 \leq z \end{matrix} \right. \]](form_51.png)
![\[ Repetir: \qquad \mathbf{w} \leftarrow \mathbf{w} - \alpha \left\{ \frac{1}{L} \mathbf{R}^{T} \phi_{\mathbf{y}}(\mathbf{R}\mathbf{w}) \quad + \quad \frac{\lambda}{N} \mathbf{I}_b\mathbf{w} \right\}. \]](form_52.png)
| [in] | Conf | Valores de configuracion de la iteracion. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector resultados . |
| [in] | W0 | Primeiro valor de . |
| Pds::Vector Pds::LogisticModel::FittingOrtogonalIG | ( | const Pds::Matrix & | X, |
| const Pds::Vector & | Y, | ||
| unsigned int | MinID | ||
| ) |
Calculo de pesos.
![\[ \mathbf{X}= \left( \begin{matrix} \mathbf{x}_1^{T}\\ \mathbf{x}_2^{T}\\ \vdots\\ \mathbf{x}_L^{T}\\ \end{matrix} \right)\equiv \left( \begin{matrix} \mathbf{v}_1& \mathbf{v}_2& \hdots& \mathbf{v}_N& \end{matrix} \right), \qquad \mathbf{y} = \left(\begin{matrix} y_1\\ y_2\\ \vdots\\ y_L\\ \end{matrix}\right), \]](form_53.png)
![\[ \begin{array}{l} for(n=0;n<N;n++)\\ \{\\ \qquad \mathbf{y_s} \leftarrow \mathbf{y}\\ \qquad Sort~ascending~\mathbf{v}_n~and~rearrange~\mathbf{y_s};\\ \qquad \{ID_{n},IG_{n},Sign_{n}\}\leftarrow GetBestInformationGainID(\mathbf{y_s},0.5,MinID);\\ \qquad umbral_{n}\leftarrow \mathbf{v}_n[ID_{n}]\\ \}\\ ~\\ n_{opt}\leftarrow arg_n max~IG_{n}\\ ~\\ if(Sign_{n_{opt}}==0)\\ \qquad w_0 \leftarrow \mathbf{v}_{n_{opt}}[ID_{n_{opt}}] \\ \qquad w_{n_{opt}} \leftarrow -1 \\ else\\ \qquad w_0 \leftarrow -\mathbf{v}_{n_{opt}}[ID_{n_{opt}}] \\ \qquad w_{n_{opt}} \leftarrow 1 \\ ~\\ \mathbf{w} \leftarrow (w_0,~w_1,~w_2,~...,w_N); \\ return ~\mathbf{w}; \end{array} \]](form_54.png)
| [in] | X | Vector de datos . |
| [in] | Y | Vector de datos . |
| [in] | MinID | Cantidad minima de muestras en cada grupo separado. |
si el cálculo es posible o una vacio si no. | Pds::Vector Pds::LogisticModel::FittingGradientIG | ( | Pds::IterationConf & | Conf, |
| const Pds::Matrix & | X, | ||
| const Pds::Vector & | Y, | ||
| const Pds::Vector & | W0 | ||
| ) |
Calculo de pesos.
![\[ \frac{\partial C(\mathbf{w})}{\partial \mathbf{w}} \equiv Pds::LogisticModel::GradientCostInformationGain(\mathbf{w},\mathbf{X},\mathbf{y},h) \]](form_55.png)
![\[ Repetir: \quad \mathbf{w} \leftarrow \mathbf{w} + \alpha \frac{\partial C(\mathbf{w})}{\partial \mathbf{w}} \]](form_56.png)
| [in] | Conf | Objeto de configuracion de iteraciones. |
| [in] | X | Matriz con los vectores de datos (muestras) en las lineas. |
| [in] | Y | Vector de datos de salida. |
| [in] | W0 | Vector inicial de pesos. |
si el cálculo es posible o una vacio si no. | Pds::DiagnosticCurves Pds::LogisticModel::LearningCurves | ( | Pds::IterationConf & | Conf, |
| const Pds::Matrix & | Xtr, | ||
| const Pds::Vector & | Ytr, | ||
| const Pds::Matrix & | Xcv, | ||
| const Pds::Vector & | Ycv, | ||
| double | percent | ||
| ) |
Retorna learning curve.
![\[ \mathbf{R} \leftarrow [\mathbf{1}\quad \mathbf{X}]\]](form_57.png)
![\[ h_{\mathbf{w}}(\mathbf{X}) \leftarrow Sigmoid(\mathbf{R} \mathbf{w})\]](form_58.png)
| [in,out] | Conf | Valores de configuracion de la iteracion. |
| [in] | Xtr | Datos X de entrenamiento. |
| [in] | Ytr | Datos Y de entrenamiento. |
| [in] | Xcv | Datos X de cross-validation. |
| [in] | Ycv | Datos Y de cross-validation. |
| [in] | percent | Porcentaje de datos testados. |







 1.9.2
1.9.2